개인화 마케팅을 위한 360도 고객뷰 구축 가이드
(참조 자료: How to Get a Customer 360 View for a Personalization Initiative)
고객 개인화(Customer personalization)는 이러한 경쟁적인 비즈니스 환경에서 앞으로 나아갈 방향임은 분명합니다. 아마존, 넷플릭스, 스포티파이 등 글로벌 IT 기업들은 초개인화에 집중하고 있는 가운데, 여타의 다른 기업들도 수익성을 유지하고 강화하기 위해 개인화된 경험 구축에 나서고 있습니다. 그러나 한 가지 문제가 있는데요, 대부분의 기업들은 아직 통합된 고객 뷰(Customer View)를 보지 못한다는 점입니다.
Marketing Week가 진행한 조사에서 북미 내 57%의 기업들이 아직 360도 고객 뷰를 구축하지 못하였다고 하는데요, 76%의 기업들이 단일 고객 뷰가 조직에 매우 중요하다고 발표한 바 있습니다.
360도 고객 뷰(통합 또는 단일 고객 뷰라고도 함)는 조직의 애플리케이션과 시스템에 흩어져 있는 모든 고객 데이터의 통합 버전입니다. 대부분의 기업에서 품질을 보장하면서도 다양한 소스에서 고객 데이터를 수집하는 것은 성공적인 개인화 마케팅을 위한 첫 걸음입니다.
초개인화(hyper-personalization)의 가장 근본 기반은 고객 데이터의 통합입니다. 개인화된 서비스를 제공하기 위해서는 디바이스, 애플리케이션, 서드 파티 벤더, 시스템과 소스에서 데이터를 수집해야 합니다. 그러나 단순히 데이터를 수집하는 것은 해결해야 할 여러 문제 중 하나일 뿐입니다. 기업들의 많은 디지털 전환 이니셔티브 실패에는 정제되어 있지 않고 중복된 데이터 처리가 그 중심에 있습니다.
만약 개인화 이니셔티브를 추진하고 있다면 이 글은 고객 데이터를 의도된 목적에 사용하기 전에 먼저 어떤 고객 데이터를 확보하고 이를 활용해야 하는지에 대해 가이드를 드릴 수 있을 것입니다.
고객 데이터의 이해
여러 소스에서 온 사용자 기록를 집계하고 고객이 기업과 가졌던 인터렉션, 즉 모바일, 앱, 웹사이트 또는 소매 매장에 이르기까지 고객이 다양한 접점에서 인터렉션들을 완전히 파악할 수 있는 중앙 집중식 기록을 만드세요.
이론적으로 단순하게 들리겠지만 이것은 어려운 과정입니다. 부분적으로는 기업이 데이터를 저장하는 방식때문이기도 하고 부분적으로는 기업들이 여전히 잘못 관리된 데이터 프로세스의 거미줄에 걸려 있기 때문입니다.
한 기업이 고객 데이터를 저장하기 위해 여러 에셋 관리 시스템을 사용하는 것은 드문 일이 아닙니다. 예를 들어, 여러 부서가 있는 기업들은 각자의 목표를 달성하기 위해 Salesforce, HubSpot 그리고 Fusion 등의 서드파티 소프트웨어를 사용할 수 있습니다. 어떤 기업은 심지어 고객 정보를 저장하기 위해 자사의 ERP나 데이터 시스템을 위해 서드 파티 벤더 프로그램을 사용할 수도 있습니다. 팀은 데이터 손실과 데이터 품질 저하의 위험을 감수하면서 중요한 마감 기한을 맞추기 위해 데이터를 정신없이 가져오거나 교환합니다.
예를 들어, 한 보험 회사가 기존 고객에게 대학에 진학하는 자녀를 위한 새로운 의료 보험 계획을 시작하는 경우를 들어봅시다. 이 계획을 수립하기 위해 기업은 가족 상태, 소득 수준, 건강 상태 및 기타 관련 사항과 같은 필수 고객 데이터에 접근할 수 있어야 합니다. 이 데이터가 이미 기업의 여러 시스템에 저장되어 있을 가능성이 있지만, 기업이 데이터 준비에 있어서 진지하게 개인화에 맞게 고려하지 않았기 때문에 특정 기한 내에 이러한 계획을 실행하는 것이 어렵다는 사실을 깨닫게 되었습니다.
이 기업은 데이터 품질 관리 프레임워크를 보유하고 있지 않기 때문에 개인화를 위한 데이터 구축은 아래와 같은 어려움을 겪게 됩니다.
- 중복(Duplication): 데이터 중복은 여러가지 이유로 발생하게 됩니다. 사용자는 다른 이메일 ID를 사용하여 3번 등록할 수 있습니다. 데이터 입력 운영자는 실수로 동일한 정보를 두 번 입력할 수 있습니다. 데이터 마이그레이션 프로세스가 잘못 될 수도 있습니다. 아래 그림과 같이 중복될 경우 정확도와 고유성이 떨어져서 데이터의 완전성(data integrity)을 훼손시킬 수 있습니다. 그 결과는? 왜곡된 분석과 신뢰할 수 없는 비즈니스 인텔리전스를 얻게 될 것입니다.
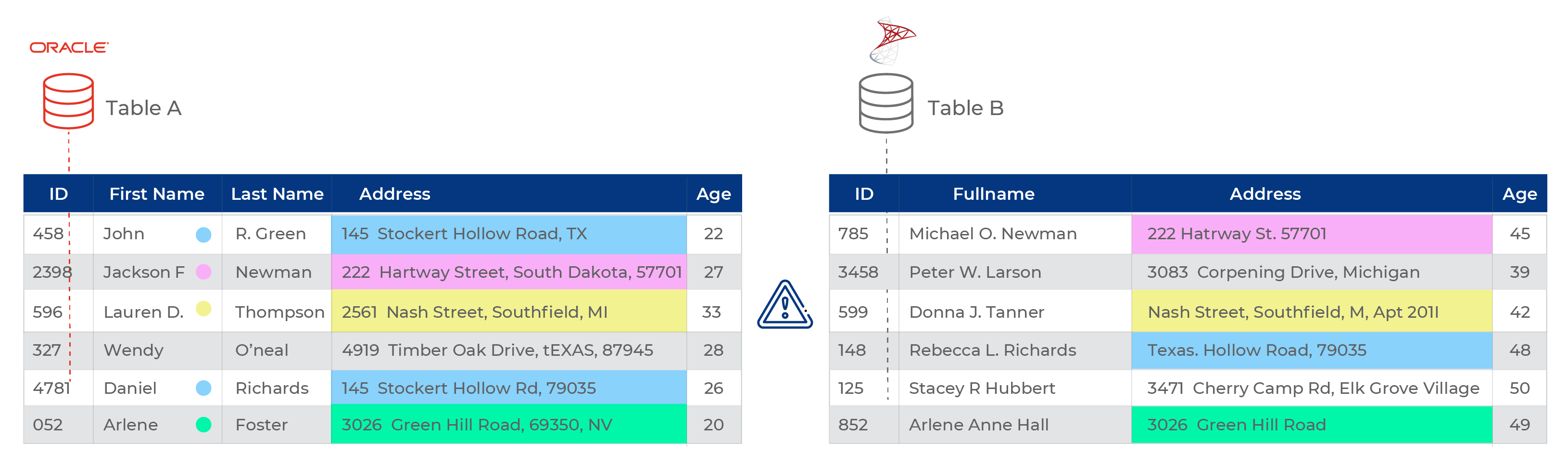
데이터 중복
- 상이한 데이터 소스(Disparate Sources): 기업이 여러 앱과 시스템을 사용하여 데이터를 수집 및 저장, 처리할 때 서로 다른 데이터가 생성되어 이는 기업이 고치기 어려운 대표적인 데이터 품질 문제가 됩니다. 이러한 데이터 차이는 완전한 고객 뷰를 구축할 수 없어 기업이 정확한 개인화 마케팅을 수행하기 어렵게 합니다.
- 지저분한 구조(Messy Structures): 포맷 문제, 오자, 철자가 틀린 이름, 불안전하거나 잘못된 구조를 가진 데이터는 완전하고 정확한 고객 데이터를 구축하게 만들지 못합니다. 데이터가 수동으로 입력되고 정의된 표준이나 제어장치가 없는 경우(예: 필드 선택을 위해 드롭다운을 사용하는 경우) 지저분한 데이터는 상당한 문제가 될 것입니다.
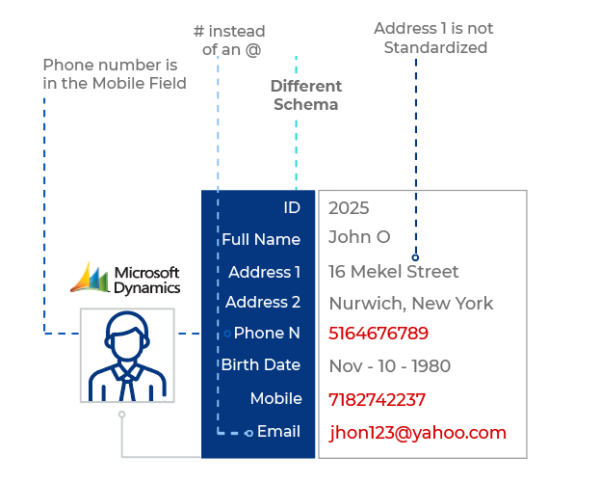
지저분한 구조(Messy Structures)
기업들이 나쁜 데이터 문제를 해결하기 위한 데이터 품질 프레임워크를 갖추고 있지 않기 때문에 답변 메일, 소송, 값비싼 실수, 부정확한 통찰력, 분석에 수백 만 달러가 낭비되고 있습니다.
이 보험회사의 경우, 첫 번째 단계는 데이터를 이해하는 것입니다. 정확하고 완전하며 유효한 정보가 있으면 데이터를 합하여 360도 고객 뷰를 만들 수 있습니다.
그들은 어떻게 이것을 성취할 수 있었을까요?
여기 두 가지 접근법이 있습니다.
데이터 품질 향상을 위한 2가지 방식
위 기업은 데이터 품질을 높이기 위해 아래와 같이 2가지 방식을 사용할 수 있습니다.
수동 방식(The Manual Approach): 데이터 전문가를 고용하여 데이터를 분류, 통합, 제거, 그리고 깔끔하게 정리하기 위한 내부 솔루션을 구축할 수 있습니다. 이 방식은 몇 년이 걸릴 수도 있습니다. 솔루션 채용, 교육, 테스트, 구현에는 수 개월이 걸릴수 있으며 데이터가 최소한 95% 정확하고 완전하다는 보장도 없습니다. 이러한 수동 방식은 한정된, 구조화된, 또는 반구조화된 기록이 있거나 알려진 정확한 값(고유 ID 혹은 시리얼 넘버)이 있는 경우 잘 작동됩니다. 데이터 세트가 더 크고 복잡한 경우 수동 방법은 데이터 분석가의 처리량을 증가시켜 데이터 분석보다는 데이터 정리에 보다 초점을 두도록 합니다.
디지털 방식(The Digital Method): 데이터 품질 문제를 해결하기 위한 디지털 솔루션이 시장에 많이 나와 있습니다. 데이터를 관리하는 데 필요한 몇 가지 유형의 소프트웨어들을 활용할 수 있는데요, 특정 데이터 웨어하우징 애플리케이션과 함께 작동되도록 설계된 네이티브 솔루션이 있습니다. 그리고 직원들이 여러 데이터 소스에 접근, 정리 및 변환할 수 있도록 설계된 자체 서비스 데이터 품질 관리 소프트웨어도 있습니다. 이러한 솔루션은 비즈니스 사용자를 위해 설계되었으며 복잡한 데이터를 통합하고 각기 다른 데이터 정의를 일치화하고, 이러한 데이터를 하나의 플랫폼에서 정리, 구문 분석, 표준화 및 통일화시키기 위해 알고리즘 조합을 사용합니다.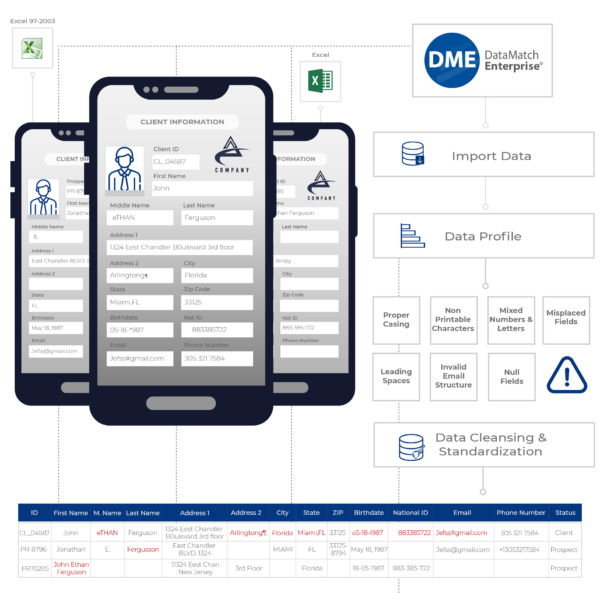
어떤 방법을 선택하든 예산, 데이터 복잡성, 리소스의 가용성 및 프로젝트에 할당하는 시간에 따라 달라집니다. 자동화된 품질 솔루션이 비즈니스 성과를 향상시키는 동시에 상당한 운영 비용을 절감하는데 도움이 될 것이라는 점은 언급할 가치가 있습니다. 내부 직원들은 빈약한 데이터 리스트를 일일이 수동으로 정리하는데 많은 시간을 할애할 필요가 없어졌습니다. 이제 비즈니스는 암암리에 이러한 데이터를 운영할 필요가 없습니다. 데이터 품질을 고객 개인화 이니셔티브의 최우선 순위로 삼을 때 진정한 데이터 중심의 비즈니스로 탈바꿈 될 것입니다.
고객 개인화 이니셔티브를 추진하기 위한 데이터 활용
가트너는 2020년까지 모든 데이터 분석 프로젝트의 40% 이상이 고객 경험 측면과 관련될 것으로 예상하고 있습니다.
그렇기 때문에 고객 개인화 이니셔티브를 추진하기 위해서는 데이터, 특히 고품질의 조정된 데이터가 매우 중요합니다.
경험을 개인화하려면 사람, 제품, 환경, 행동, 경험, 기대 사이의 숨겨진 관계를 알아내야 합니다.
위의 보험 회사의 예시를 들면서,
그들은 벤더와 파트너사로부터 필요한 데이터를 수집하는데 2개월이 걸렸습니다. 다음으로 그들은 이 데이터를 정리하고, 중복 데이터를 제거하고, 정상화해야 했습니다. 이 과정은 그들이 상당한 시간과 인력을 절약할 수 있는 셀프 서비스 도구를 사용했을 때 단 3주 밖에 걸리지 않았습니다. 마침내, 3개월 간의 데이터 정리, 데이터 통일, 통합, 제거 프로세스 후에, 기업은 고객에 대한 통합 기록을 얻을 수 있었습니다.
그 결과는?
타깃 오디언스를 세분화하고 대학을 다니는 자녀를 둔 부모들을 위한 완벽한 보험 계획을 세울 수 있었고, 효과적인 이메일 마케팅 캠페인을 벌였으며, ROI를 2배 더 높일 수 있었습니다. 고객들은 긍정적인 반응이 더 좋았습니다.
어떻게 시작할 수 있을까요?
개인화 이니셔티브를 시작하고 싶다면 우선 작게 시작하는 것이 가장 좋습니다. 기업 내 모든 데이터를 하나하나 샅샅이 볼 필요는 없으며 제공하고자 하는 서비스 종류에 필요한 데이터 유형을 식별하기만 하면 됩니다. 도움이 되는 몇 가지 팁을 소개합니다.
작게 시작하기(Start Small): 관리할 수 있는 프로세스를 만드세요. 500개의 고객 기록을 추출하여 품질 문제에 대해 평가하고 이러한 문제를 해결하는데 얼마나 많은 시간이 걸리는지 기록하세요.
접근 방식 결정하기(Decide on the Approach): 3D에 대한 데이터를 평가하면 데이터를 수정하는데 사용할 접근 방식을 결정하는데 도움이 될 것입니다. 확인된 정확한 값이 없고 데이터가 복잡하고 중복이 15~25%(500건 중 불량 기록이 125건)라면 수작업으로 고치는 대신 자동화된 솔루션을 사용해야 합니다.
적합한 도구에 투자하기(Invest in the Right Tools): 엑셀 또는 구글 스프레드시트를 사용하여 이 작업을 제대로 수행할 수는 없습니다. 여러 소스(CRM, 거래 데이터, 동작 데이터)에서 데이터를 가져오려면 데이터를 통합하고 중복 제거하며 복잡한 데이터를 정리할 수 있는 도구에 투자해야 합니다.
데이터 수정하기(Fix Your Data): 이것을 반복하지 않을 수 없습니다. 나쁜 데이터는 모든 면에서 큰 병목 현상이 될 것입니다. 360도 고객 뷰를 원하든 원하지 않든, 데이터 품질을 우선시해야 할 것입니다. 수많은 기업들이 잘못된 데이터 때문에 (수백 만 달러를 낭비한 채) 실패했습니다. 따라서 홍보 캠페인처럼 정상적인 것이든, 연례 보고처럼 중요한 것을 위한 것이든, 믿을 수 있는 자료가 필요합니다.
마스터 기록 생성 또는 자동 정리(Create a Master Record & Automate Cleaning): 데이터를 정리 및 중복 제거했으면 마스터 레코드를 만드세요. 그런 다음, 도구를 선택하여 데이터 정리를 자동화할 수 있습니다. 더 나아가, 여러분은 또한 고객 데이터를 풍부하게 하기 위해 추가적인 고정 자료, 인구 통계 자료 또는 행동 자료로 이 기록을 증가시킬 수 있습니다.
그 시작은 특히 조직의 데이터가 정렬되지 않는 경우, 엄청난 노력처럼 보일 수 있지만, 적합한 계획과 리소스를 통해 일반적인 리스트를 기록을 강력한 지적인 자산으로 만들 수 있으며, 이를 통해 ROI를 높이고, 고객 경험을 향상시키고, 비즈니스 성과를 높일 수 있을 것입니다.
결론
짧게 결론을 내리자면, 고객들의 선택을 받고 싶다면 그들이 필요로 하는 경험을 제공해야 합니다. 하지만 그들을 설득하기 전에 데이터를 수정하고 ‘데이터 드리븐(data-driven)’이나 ‘데이터 센트릭(data-centric)’과 같은 모호한 용어에 의미를 부여하여 시대를 앞서가세요.
*마케팅 자료 및 기타 상담 문의: parkmg85@hanmail.net
*취업 준비생 및 사회 초년생 마케터를 위한 1:1 마케팅 실무 팁 & 직무 커리어 코칭을 진행하고 있습니다. 수강생 개인 니즈에 따라 맞춤형으로 진행되고 있으니 자세한 사항과 교육 신청은 여기에서 확인하세요.

